Javul a Spotify hangalapú podcast-keresője
Sokkal több és relevánsabb találatok jelenhetnek meg Spotify-on a podcast epizódok keresésekor. A kutató-fejlesztő csapat részletes technikai bejegyzésben mutatja be, hogyan vezeti be a természetes nyelvi keresést a szolgáltatásba.
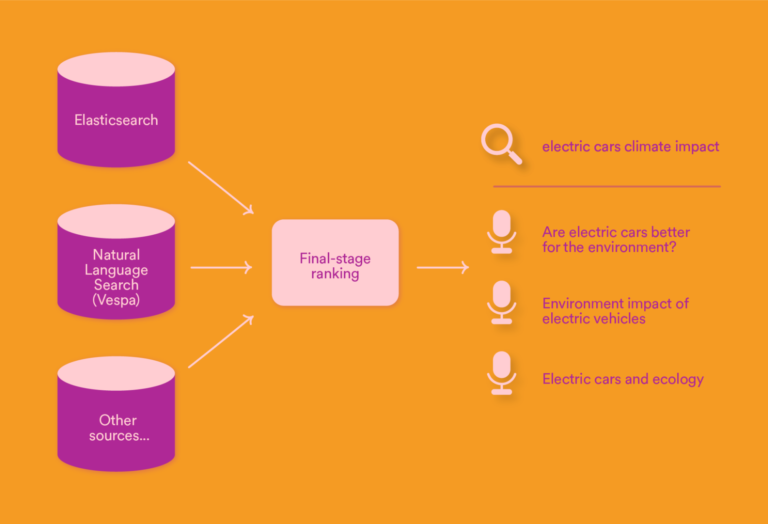
Eddig a Spotify podcastjai közt viszonylag nehézkes volt a keresés, ami nem volt összhangban a vállalat piaci terjeszkedési terveivel. A keresőszavak beütése után ugyanis a címben csak ugyanazokat a szavakat tartalmazó találatokat kaptuk a háttérben működő Ealsticsearch segítségével. A vállalat kedvenc példájával élve az "elektromos autók klímahatása" nem eredményezett találatot, mert egyik podcast címében sem szerepeltek konkrétan ezek a szavak, miközben egyébként lehet találni a szolgáltatásban erről szóló beszélgetéseket. A probléma megoldására a Spotify fejlesztői a természetes nyelvi keresés (Natural Languge Search) vagy más néven szemantikus keresés technikáit vezették be.
A szemantikus keresés lényege, hogy konkrét kifejezések helyett többféle kapcsolatot igyekszik megállapítani a szöveges tartalmakkal, például szinonimákat és a keresett kifejezés tartalmához más módon hasonlító bekezdéseket keres. A Spotify a modellekkel való kísérletezést követően végül a Universal Sentence Encodert választotta, amelyet feltételes maszkolt nyelvi modellezés segítségével a fejlesztői több mint 100 nyelven tanítottak be (itt elérhető a TensorFlow Hubon). A többnyelvűség fontos volt a streaming cég számára, mivel a megoldást nem csak angolul szerette volna bevezetni.
Égbe révedő informatikusok: az Időkép-sztori Mi fán terem az előrejelzés, hogy milyen infrastruktúra dolgozik az Időkép alatt, mi várható a deep learning modellek térnyerésével?
Majd a saját adatok előkészítése következett a modell számára, melyhez az adattudós csapat a korábbi keresések és podcast epizódok logjait használta fel. Igyekeztek feldolgozni, hogy melyik korábbi keresés találatára kattintanak végül a felhasználók, vagyis melyik kifejezés-epizód páros bizonyult legeredményesebbnek. Továbbá megnézték, hogy az első sikertelen keresés után milyen kifejezésekkel próbálkoztak még a Spotify-használók. Ezenkívül szintetikusan és manuálisan is generáltak további keresőkifejezéseket a népszerű műsorok címe és leírása alapján. Az előkészített adatok és további negatív kifejezés-epizód párosok generálásával valósult meg a modell betanítása és beépítése a Spotify keresőjébe.
Végül a tesztek és az üzleti megfontolások alapján a streaming szolgáltató meghagyta a korábbi, pontos kifejezésekre kereső megoldását is, és a természetes nyelvi keresést csak egy plusz módszerként illesztette be. Egy rangsoroló eljárás dönt róla, hogy a felhasználó milyen találati listát lát végül, amely egyaránt tartalmazhat a konkrét kifejezésre és a szemantikus keresésre vonatkozó találatokat.
A legtöbb Spotify-hallgató már meg is kapta a szükséges frissítést a pontosabb podcast-kereséshez, és a bejegyzés szerint azt a cég az angolon kívül más nyelveken is bevezette. Az "elektromos autók klímahatása" keresésre (és más bonyolultabb kérdésekre) valóban vannak magyarul is találatok a szolgáltatásban, pedig egyik epizód sem rendelkezik konkrétan ezzel a címmel, de a találatok minőségének ellenőrzéséhez mélyebb elemzésre lenne szükség.